
What is Retrieval-Augmented Generation (RAG) and Why is Semantic Search Important?
Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by allowing them to retrieve external knowledge at query time. This means AI can generate more relevant and up-to-date responses without needing costly and time-consuming retraining. However, the effectiveness of this retrieval process depends on how well the system selects relevant information, and this is where semantic search plays a crucial role.
Traditional search methods, which rely on exact keyword matches, often fail when users phrase queries differently from how information is stored. For example, if a legal assistant searches for “case law on software patents,” a traditional search might only return documents explicitly containing those words. However, a semantic search system understands that “intellectual property rights in software” is conceptually related and should also be retrieved. This ability to find relevant information based on meaning rather than exact wording makes semantic search an essential component of modern AI applications.
Understanding RAG in Simple Terms
For those unfamiliar with the term, Retrieval-Augmented Generation (RAG) is an AI technique that improves the responses of Large Language Models (LLMs) by incorporating external knowledge at the time of a query. Instead of relying solely on what the model learned during its initial training, RAG retrieves relevant documents from a knowledge base and feeds them into the model’s context before generating a response. This allows AI to provide more accurate, up-to-date, and domain-specific answers without the need for retraining.
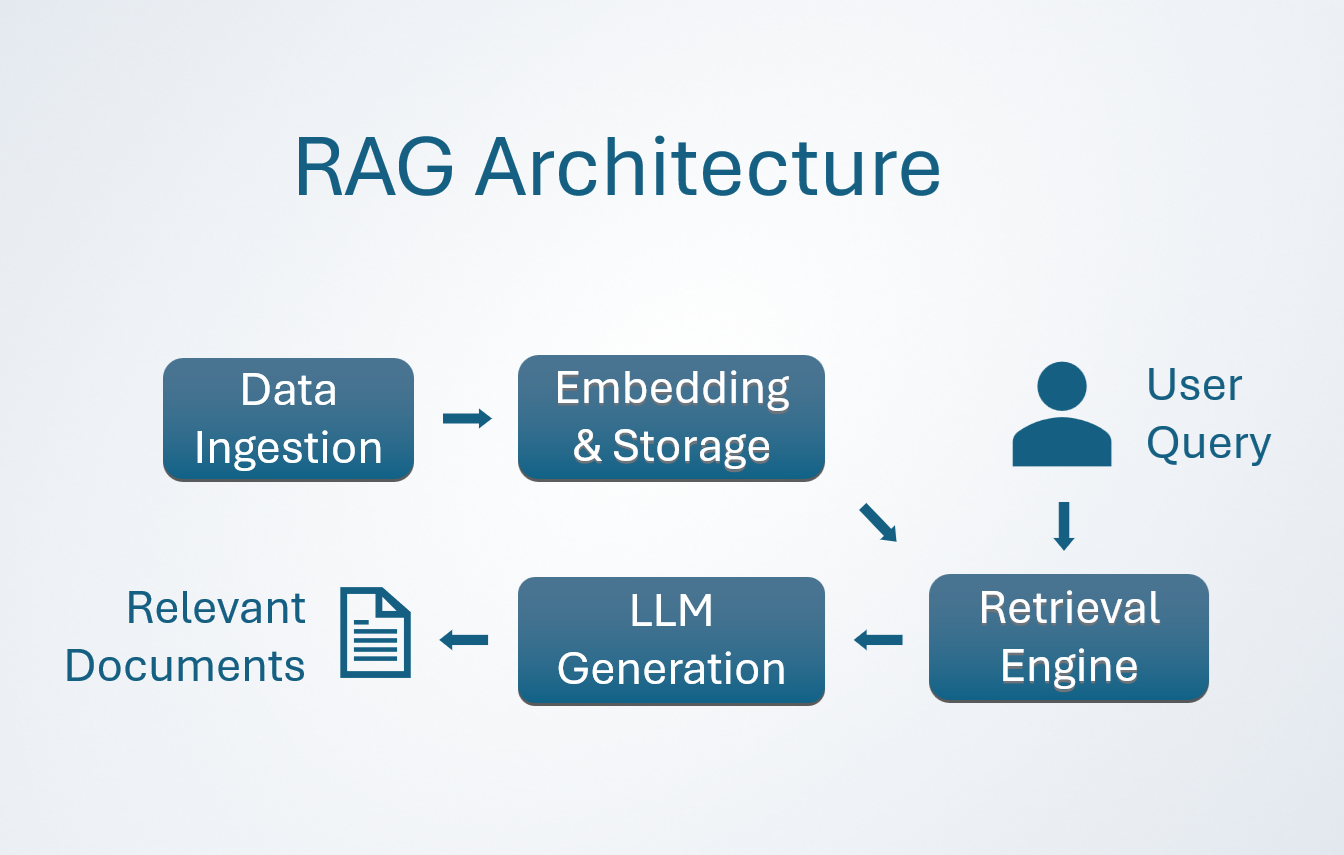
How RAG Works (Step-by-Step)
- User Submits a Query - A user asks a question or provides a prompt to the system.
- Query is Embedded - The input is transformed into a numerical representation (embedding) using an embedding model.
- Retrieval from Knowledge Base - The system searches a vector database to find semantically similar documents that may contain relevant information.
- Relevant Documents are Retrieved - The most relevant documents are selected and provided to the LLM as additional context.
- LLM Generates a Response - With the retrieved documents in its context window, the model creates a more informed and accurate response than it could with its pre-trained knowledge alone.
RAG enhances accuracy by integrating real-world, domain-specific knowledge, ensuring AI responses remain relevant and up-to-date without requiring retraining. By grounding answers in retrieved information, it minimizes hallucinations and improves reliability.
Additionally, it enables AI to process proprietary or private datasets that were not part of its original training, making it more adaptable for specialized applications.
RAG is widely used in customer support, legal research, technical documentation, and academic search systems, where access to the latest or proprietary information is crucial for high-quality responses.
How Semantic Search Works: From Keyword Matching to Meaning-Based Retrieval
To understand how semantic search differs from traditional keyword-based search, consider how students prepare for an exam.
A student has two ways to organize their study materials:
-
Index Cards (Traditional Search) - The student writes down key facts on index cards, sorted alphabetically. If they need information on “neural networks,” they flip through their neatly labeled cards to find the exact phrase. However, if the relevant information is under “Deep Learning Models,” they might miss it entirely because the wording differs.
-
A Meaning Map (Semantic Search) - Instead of rigidly categorizing facts, the student builds a concept map linking related ideas. If they need information on “neural networks,” they explore connected topics like “deep learning,” “machine learning models,” or “backpropagation,” because they understand these are closely related.
Semantic search works like the meaning map, allowing AI systems to retrieve relevant documents even when the wording doesn’t match exactly.
At the core of semantic search is a process called embedding, which transforms words, phrases, or entire documents into mathematical representations (vectors). These vectors exist in a high-dimensional space where similar concepts are closer together. For instance, “dog” and “puppy” are mapped close to each other, while “dog” and “car” are much further apart. When a user submits a query, the system converts it into a vector and then finds the most similar vectors in its database using k-Nearest Neighbors (k-NN) search. This approach ensures that the most relevant results are retrieved based on meaning rather than just word matching.
To make this process efficient, AI systems rely on vector databases like FAISS, Pinecone, or Weaviate, which are optimized for searching millions of high-dimensional vectors quickly. Without these specialized databases, performing semantic search at scale would be computationally expensive and slow.
When to Use and When to Avoid Semantic Search
Best Use Cases for Semantic Search
Semantic search is particularly useful when dealing with natural language queries, where users phrase questions in diverse ways. Unlike structured data lookups, where exact matches are necessary, semantic search excels in retrieving meaning-based information. Some ideal applications include:
- Legal AI Assistants: Instead of retrieving only documents that contain exact keywords, semantic search enables finding case law that is relevant based on legal arguments and principles, even if phrased differently.
- Biotech Research Assistants: Scientific studies often use varying terminology. Semantic search allows retrieving research papers based on similar methodologies and findings, even if the wording differs.
- Customer Support Chatbots: Users describe problems in different ways. Instead of relying on exact phrasing, semantic search matches the intent behind a query to relevant troubleshooting solutions.
These examples illustrate how retrieving documents based on meaning ensures a more relevant and effective AI response, improving user experience and accuracy.
When Semantic Search is Not the Best Fit
While powerful, semantic search is not always the best tool for the job. Some scenarios require exact matches, greater precision, or strict rules that semantic search alone cannot handle.
-
When Exact Matching is Necessary (The Safe Cracker Problem) Imagine you’re trying to open a vault with a specific passcode. If the code is 394215, but you enter 394216, the vault won’t open. No amount of semantic understanding will help-it must be an exact match. Similarly, retrieving IDs, passwords, or exact legal references requires strict keyword-based search, not semantic similarity.
-
When Small Differences Matter (The Pharmacist’s Dilemma) A pharmacist must carefully distinguish between two drugs: hydroxyzine and hydroxychloroquine. Although the names sound similar, their effects are entirely different. If an AI assistant retrieves a result based on general similarity rather than exact matching, it could lead to dangerous mistakes. This applies to medical terminology, legal citations, and technical searches where small distinctions have major consequences. A solution here is to combine semantic search with keyword filtering to ensure accuracy.
-
When Too Much Freedom Leads to Nonsense (The Overly Helpful Waiter) Imagine walking into a restaurant and asking, “What’s good here?” Instead of giving a straightforward recommendation, the overly eager waiter tells you, “If you like pizza, you should try lasagna. Also, did you know about the history of tomatoes?”
Similarly, semantic search can sometimes return results that are loosely related but not actually useful. For instance, searching for “data encryption” might retrieve documents about privacy laws rather than actual encryption techniques. To prevent this, AI systems can use re-ranking, thresholding, and hybrid filtering to prioritize truly relevant results.
-
When Results Are Too Subjective (The Book Recommendation Trap) If you ask a bookstore clerk, “I want a good book,” they might suggest a philosophy book when you were actually looking for science fiction. Semantic search faces a similar issue-it may retrieve technically relevant results that are personally wrong for the user. Solutions include personalization (adapting results to user history) and allowing feedback mechanisms for refinement.
-
When Data is Too Sparse (The Lonely Lighthouse Problem) A lighthouse is only useful if there are other nearby landmarks to navigate by. Similarly, semantic search relies on a rich dataset to draw meaningful connections. If there isn’t enough training data, the AI might struggle to find relevant relationships. This issue commonly arises in niche fields with limited documentation. In such cases, hybrid approaches-combining traditional keyword search with semantic techniques-can improve performance.
How to Evaluate and Optimize Semantic Search: The Rescue Dog Analogy
Choosing the right semantic search system is like training a search-and-rescue dog. Different dogs have different strengths-some are fast but imprecise, running in the wrong direction based on a weak scent. Others are slower but more methodical, ensuring they don’t miss any clues. Some excel in forests, while others are better suited for urban environments. Similarly, a semantic search system must be evaluated and optimized based on key performance metrics to ensure it performs well for its intended purpose.
1. Finding the Right Target (Precision vs. Recall)
Imagine a rescue dog searching for a missing hiker. There are two possible errors:
- The dog fails to find the person (low recall).
- The dog finds the wrong person (low precision).
A dog that only finds the exact missing hiker has high precision but might overlook others in need. A dog that alerts on anything remotely human-shaped has high recall but risks bringing back false positives. The ideal balance depends on the scenario:
- A legal search tool prioritizes high precision to ensure no irrelevant cases appear in the results.
- A medical research search might favor high recall, ensuring that all potentially useful studies are retrieved.
For an AI system, tuning precision and recall ensures users get the most relevant results without missing important information.
2. Speed: The Race Against Time (Latency & Throughput)
If a rescue dog takes six hours to find someone lost in the snow, they might freeze before being rescued. If the dog is extremely fast but constantly runs in the wrong direction, it’s also ineffective. In semantic search, speed is just as important as accuracy.
- Latency (Time per Search): If an AI assistant takes too long to retrieve answers, users lose patience. In real-time applications like chatbots, low latency is critical for a smooth experience.
- Throughput (Number of Searches Per Second): In high-traffic environments like e-commerce or customer support, an AI system must handle thousands of queries without slowing down.
Just like a well-trained rescue dog balances speed and accuracy, an AI system must optimize search efficiency without sacrificing quality.
3. Adaptability: The Right Dog for the Terrain (Embedding Quality & Domain-Specificity)
Not all rescue dogs work in the same environments. A mountain rescue dog excels in rugged terrain, while a water rescue dog is trained for floods and oceans. Similarly, different embedding models perform better in different domains.
- Pre-trained embeddings work well for general topics but may struggle with highly specialized fields like medicine or law.
- Fine-tuned embeddings adapt to domain-specific vocabulary, improving accuracy in niche industries.
For example, a general AI assistant might retrieve “AI ethics guidelines” for a search about machine learning fairness, but a finance-focused AI should prioritize “regulatory compliance for AI in banking” instead. Choosing the right embedding model ensures the AI retrieves truly relevant information for its intended field.
4. Managing Resources: The Backpack Problem (Storage Efficiency & Indexing Methods)
A rescue dog can only carry so much equipment-a heavier backpack slows it down, while too little gear leaves it unprepared. Similarly, semantic search systems must balance storage efficiency and speed.
- Vector Storage: Storing millions of high-dimensional embeddings requires significant memory. Some models generate smaller, more compact vectors to save space.
- Indexing Efficiency: Just like rescue dogs use their scent memory to track lost hikers efficiently, AI systems use optimized search structures (like HNSW graphs) to speed up retrieval without excessive storage costs.
The goal is to ensure the system is fast, efficient, and capable of handling large-scale searches without unnecessary computational overhead.
Conclusion
Semantic search is a powerful enhancement for Retrieval-Augmented Generation (RAG) systems, allowing AI to retrieve relevant information based on meaning rather than exact words. By replacing rigid keyword matching with vector-based similarity, AI can offer more accurate, context-aware responses.
However, semantic search is not a universal solution. Some scenarios require strict keyword matching, hybrid approaches, or additional filtering mechanisms. Understanding when and how to apply semantic search ensures that AI systems are both efficient and accurate, improving their real-world applicability across various industries.
